OpenGL复习(法线贴图、视差贴图、HDR、实例化)
法线贴图
- 优化:增加物体的细节,如果直接增加顶点,将产生大量开销,而通过纹理,开销少了很多,但由于网格表面实际是平整的,所以光照看起来不够真实,凹凸表面是一样的亮度,为了让代价最小,仍然用贴图,根据贴图的法线方向光照计算,总之就是用小的代价使得纹理的光照看起来更真实
- 存储:法线贴图每个像素存储法线方向,xyz用rgb表示,法线贴图大部分是蓝色的,因为法线一般垂直于物体表面,指向虚拟z轴
- 问题:由于法线贴图存储的法线方向永远固定不变,当物体表面并非正对xy平面时,将获得错误的光照结果
- 空间区分:
- 局部空间:每个三角形网格独立的空间(原点+坐标系)
- 世界空间:所有三角形网格共用的空间
- 切线空间: 每个三角形网格独立的空间,由3个坐标轴TBN组成:tangent、bitangent、normal,TB在三角形表面上,N垂直三角形表面与法线方向一致,3者是正交的(可以保证uv映射不发生扭曲)(三角形一定是共面的)
- TBN矩阵:
- 计算TBN

- e是三角形平面上的任意一条边,deltauv是边的两个顶点在纹理空间中的uv差值,TB是要求的向量
- e的定义和TB计算在局部空间中,用最原始的数据计算,避免了复杂变化的影响,是最简单的计算选择,并且它可以预计算出来
- 构建TBN矩阵
- N通常作为顶点属性直接提供,不用计算,如果没有提供,可以根据两个边叉乘计算出来
- 由于TBN是局部空间的,还应应用M变换到世界空间,才能和已在世界空间的三角形对齐
- vec3 T = normalize(vec3(model * vec4(tangent, 0.0)));
- vec4:TBN本身是向量vec3,不受位移影响,对于mat4的矩阵,有两种方式,TBN变为vec4 w分量为0、mat3(model),
- vec3:对于mat4 * vec4 得到4行1列的向量,因为对于向量来说w分量无意义,所以可以直接丢弃
- normalize只关心方向
- mat3(T, B, N);构建TBN矩阵
- 使用TBN矩阵
- 方式一:法线贴图向量*TBN矩阵 从切线空间转换到世界空间
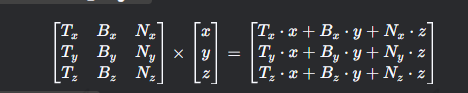
- mat3 * vec3
- 法线对每个像素都不一样,所以要对每个像素分别计算,需要在fs中操作,消耗性能
- 方式二:世界向量*TBN的逆矩阵,根据逆矩阵性质将转换到切线空间
- 由于像lightpos,viewpos……对于每个像素都一样,在vs中就可以计算,性能较好
- 方式一:法线贴图向量*TBN矩阵 从切线空间转换到世界空间
- 计算TBN
- 法线矩阵:逆转置矩阵:
- 法线不能简单*M
- 法线是向量,位移并不影响向量,直接左乘mat3 可以减少计算量,提高性能
- 当M矩阵中包含非均匀的缩放时,法线长度改变,但可以单位化修复,法线方向改变,不再垂直于表面,将造成错误的光照计算结果
- 为什么方向会因为非均匀的缩放发生改变?想象一个平面,连接对角方向,非均匀的缩放平面对角方向发生改变
- 逆转置推导
- 原三角形切向量T垂直于N,因此 T · N == 0
- 希望变换后 T’ · N’ == GN · MT, T可以直接*M,法线N要特殊的G变换,才能让变换后依旧垂直于T
- GN · MT == (GN)ᵀ * MT, 向量左乘矩阵结果仍为向量,两个列向量点乘 == 行向量和列向量叉乘
- (GN)ᵀ * MT == Gᵀ * Nᵀ * M * T, 括号可以展开
- 当Gᵀ * M == I(单位矩阵)时,GN · MT == T’ · N’(前面的等价) == Nᵀ * T(I被消掉) == N · T(叉乘转为点乘) == 0 , 也就是Gᵀ * M == I时,T’ · N’ == 0,即T’ 垂直于 N’
- 因此由Gᵀ * M == I,移项Gᵀ == M^-1, 两边同时转置 G == (M^-1)ᵀ,即逆转置矩阵
- 当M为正交矩阵时,逆矩阵==转置矩阵,则(M^-1)ᵀ == (Mᵀ)ᵀ == M,这是可以直接使用M矩阵
平滑切线向量
1 2
T = normalize(T - dot(T, N) * N);//确保T与N垂直 vec3 B = cross(T, N);//重新计算副切线B
展开
- 当较复杂的网格,往往有很多共享顶点,将切线平均化通常能获得更好更平滑的结果,但TBN向量可能不再是正交矩阵了,我们可以进行重正交化
视差贴图
- 优化:和法线贴图一样,也是对纹理光照的优化,使之具有深度感
- 高度贴图:0黑色较低,1白色较高
- 深度贴图:0黑色较近,1白色较远
- 存储:存储float深度值
- 思想:它不需要额外的顶点数据根据深度值来实际偏移,而是采用缩放视线的方式,来找到新的纹理坐标去采样
- 缩放值:通过像素深度值,缩放视线,深度越远缩放越大,但是当深度落差过大时,在这种估算方式下看起来不太真实
- 找到新纹理坐标:新视线终点 垂直于物体表面 对应的纹理坐标
切线空间:但上述方式很难实现,利用切线空间,把视线方向变换到切线空间,那么纹理坐标偏移量即为v.xy(注意,深度值不同于法线,从切线空间转换到世界空间的方式不可行)
1 2 3
float height = texture(depthMap, texCoords).r;//像素的深度值 vec3 p = viewDir.xy / viewDir.z * height;//视线看向每个像素方向都不同 return texCoords - p;
展开
- p向量和新纹理坐标:
- 用height缩放viewDir.xy,
- /z是为了符合视线关系,首先viewDir被归一化,因此z在0.0到1.0之间,
- 期望当视线平行于表面,应更大程度的缩放,垂直于表面,缩放程度较小
- 当平行于表面,z较小,缩放结果大,垂直于表面,z较大,缩放结果小,符合预期
- 根据新的纹理坐标查找颜色纹理和法线纹理,获得颜色和法线方向,用于之后的运算
- 边缘失真:边缘位置计算新纹理坐标可能会超过0——1的范围,可以直接discard丢弃这个片段
- 陡峭视差映射:
- 上面说过当深度落差过大时,在这种估算方式下看起来不太真实,可以使用陡峭视差映射
- 深度的范围是0——1,把它均匀的分割层,比如n层,层深度即为1/n, 当前层深度从0开始,每次+层深度,viewDir.xy是最初的纹理坐标位置,viewDir.xy/n作为每次纹理坐标偏移量
- 把每个深度层(从上到下遍历)和像素深度值对比,直到某层深度>=像素深度值,可以使用到这层的pn来偏移纹理坐标
- 可以想象之前直接用像素深度值作为偏移量,而现在不断偏移像素,用最适合的深度值作为偏移量
1
float numLayers = mix(maxLayers, minLayers, abs(dot(vec3(0.0, 0.0, 1.0), viewDir)));
展开
- 动态调整层数量:视线越接近于z,越垂直,点乘结果越大,层数量越小
- 视差遮蔽映射:
- 陡峭视差有问题,由于采样是有限的,会遇到明显断层问题(没有平滑过渡),可以通过增加样本解决,但会花费很多性能
1 2
float weight = afterDepth / (afterDepth - beforeDepth); vec2 finalTexCoords = prevTexCoords * weight + currentTexCoords * (1.0 - weight);
展开
- 另一种方式通过线性插值,根据当前层和像素深度值差值,下一层差值,作为权重,获得最终的纹理坐标
HDR(High Dynamic Range)高动态范围
- 显示器的颜色值在0——1 LDR(Low Dynamic Range,低动态范围)之间,如果那些超过1的颜色被直接约束到1,将损失很多的细节,因此我们应允许暂时保留颜色值,然后通过一定方式合理转换到范围之间,从而防止损失细节,这个过程叫做色调映射(Tone Mapping)
- Reinhard色调映射算法:hdrColor / (hdrColor + vec3(1.0));
- Exposure曝光参数:vec3(1.0) - exp(-hdrColor * exposure);低曝光值会显著减少黑暗区域的细节,高曝光值会显著减少亮部区域的细节,
实例化
- 场景有大量使用相同顶点数据的物体,每一个物体调用一次drawcall,从CPU到GPU通讯极为消耗性能
- 实例化技术,可以将数据一次性发送给GPU(drawcall),让GPU绘制多个物体
- 使用glDrawArraysInstanced/glDrawElementsInstanced实例化版本的drawcall
- 使用gl_InstanceID可以控制每个实例化对象
- 实例化数组:每个对象不同的部分通过uniform 传递数组的方式,但当大量物体时会超过uniform数据大小上限,实例化数组被定义为顶点属性,将数组传给shader
本文由作者按照 CC BY 4.0 进行授权