C++(1·内置指针、语句、右值引用)
内置指针
- 指针本质:通过间接指向和操作内存,提供了更灵活的操作能力
- 1级指针,2级指针:type** 指针的指针
- 指向:
- 对非常量指针可以指向:非常量左值,将亡值(通过右值引用间接)
- 对常量指针可以指向:非常量左值,常量左值,将亡值(通过右值引用间接)
- 常量指针可以指向:非常量左值
- 指向常量的常量指针可以指向:非常量左值,常量左值,将亡值(通过右值引用间接)
- 指针作用:(间接操作的优势,防止拷贝,增加灵活性)
- 作为函数参数返回值、数组和指针的转换时,指针类型元素的数组(虚表),……使用已分配内存时,可以高效传递对象,避免拷贝的内存消耗
- 可以灵活修改指向
- 非指针只能静态绑定,基类指针由于间接指向内存,可以灵活修改指向,可以动态绑定,实现动态多态
- 使用函数指针实现回调函数,可以接受不同的函数地址,有更高的灵活性
- 动态生命周期管理,指向不同的内存,灵活性较高
1 2 3 4 5 6 7 8 9 10
class A { A a;//❌ 错误 A* a = new A;//❌ 错误 A* a;//✅ 正确 A& a;//✅ 正确 static A a;//✅ 正确 static A* a;//✅ 正确 }; A A::a; A* A::a = new A;
展开
- 在实现链式数据结构时通常需要next(链表,树,图),
- A a;/A* a = new A;,内存分配无限循环(A a.a.a……),无法确定sizeof(A),不被允许,
- A* a = new A;也会无限循环,不允许
- A* a,不立即初始化(在成员函数内部初始化),指针大小4/8字节,可以计算内存,被允许
- static A a;因为它只有一份,存放在静态区
- static A* a; A* A::a = new A; 被允许,因为它只有一份,存放在静态区
复杂指针阅读
右左法则:从标识符开始,先向右看,然后向左看,每当遇到圆括号时,就调转阅读方向,当括号内的内容解析完毕,就跳出这个括号,重复这个过程直到表达式解析完毕
1 2 3 4 5 6 7 8 9
int i;//从i开始,右侧没有看左侧,则i是int类型 int *a[3];//从a开始,右侧说明a是包含3个元素的数组,左侧说明每个元素是int*类型 int (*a)[3];//从a开始,右侧是括号,左侧说明a是指针,左侧遇到括号,右侧说明a指向包含3个元素的数组,左侧表明每个元素是int类型 int **p;//p是指针,指向的对象类型也是指针(二级指针),此指针指向的类型是int int *foo();//从foo开始,右侧说明foo是函数,左侧说明返回类型是int* int (*foo)();//从foo开始,右侧是括号,左侧说明foo是指针,左侧遇到括号,右侧说明foo指向函数(函数指针),左侧说明返回类型是int int (*(*vtable)[])();//vtable是指针,指向数组,每个元素是指针类型,指向函数(函数指针),左侧说明此元素返回类型是int int *(*p(int))[3];//p是包含int类型参数的函数,返回类型为指针,此指针指向包含3个元素的数组,每个元素类型是指针,指向int类型对象 int (*(*p)(int))(int);//p是指针,指向包含int类型参数的函数,函数返回类型为指针,指针指向包含int类型参数的函数,函数返回类型为int
展开
- int p;
- 从p开始向右看,没有,向左看,p是int类型的变量
- int *p;
- 从p开始向右看,没有,向左看,p是指针,再向左看,p指向int类型元素
- int *p[3];
- 从p开始向右看,p是有3个元素的数组,向左看,元素类型为int*
- int (*p)[3];
- 从p开始向右看,遇到圆括号时,向左看,p是指针,跳出括号,先向右看,p指向有3个元素的数组,向左看,元素类型为int
- int **p;
- 从p开始向右看,没有,向左看,p是指针,向左看,p指向int*
- int p(int);
- 从p开始向右看,p是参数为int类型的函数,向左看,函数返回类型为int
- int (*p)(int);
- 从p开始向右看,遇到圆括号时,向左看,p是指针,跳出括号,先向右看,p指向参数为int类型的函数,向左看,函数返回类型为int
- int (p(int))[3];
- 从p开始向右看,p是参数为int类型的函数,向左看,函数返回类型为指针,跳出括号,先向右看,函数返回的指针指向有3个元素的数组,向左看,元素类型为int*
- int ((p)(int))(int);
- 从p开始向右看,遇到圆括号时,向左看,p是指针,跳出括号,先向右看,p指向参数为int类型的函数,函数返回类型为指针,跳出括号,先向右看,函数返回的指针 指向参数为int类型的函数,函数返回值为int
函数指针
- 定义函数指针:return_type (*p) (parameter_list);
- 函数指针数组(虚表):return_type (*p[n]) (parameter_list)
- 函数指针数组的指针(虚指针):return_type ((p)[n]) (parameter_list)
- 初始化/赋值: = &func_name <==> = func_name
- 调用函数:(*p)(parameter_list) <==> p(parameter_list)
- typedef
- 使用 typedef 定义函数指针,代码看起来更简洁,也更不容易出错, 并且函数指针作为函数返回值,必须使用typedef声明的类型
- 声明函数类型: typedef return_type (func_name)(parameter_list);
- 声明函数指针类型: typedef return_type (*ptr_name)(parameter_list);
- 定义和初始化函数指针:
- func_name* p = &func / func(因为函数会隐式转换);
- ptr_name p = &func / func;
- 调用:p(parameter_list);
静态 vs. 动态
静态:
- 在构建时确定
- 空间小
- 不灵活
- 速度快
- 内存固定
- 自动管理
动态:
- 在运行时(执行指令)确定
- 动态绑定,动态内存分配,动态链接,动态生命周期:
- 动态内存分配作用:
- 静态生命周期对象一直占用内存,造成内存浪费,在不需要时手动释放内存,避免内存浪费
- 自动生命周期对象通常情况下栈区,栈区的大小容不下过于庞大的数据,所以在堆分配内存
- 动态内存分配作用:
- 空间大
- 更灵活
- 速度慢
- 内存可变
- 手动管理
语句
循环:重复执行某段代码
遍历:遍历强调访问集合中的每个元素
迭代:迭代是循环的一次执行过程
- 条件
- if:
- if(条件){语句块}else if(条件){语句块}……else{语句块},如果,否则如果,……,否则
- 可以嵌套
- 优势:条件灵活
- 缺陷:性能较差
- 使用场景:常用于复杂判断时
- switch:
- switch(条件){case关键字 整形常量表达式:语句块;break; ……}
- 条件:允许(整形,enum类型,常量表达式),不允许(浮点,字符串,类类型)
- break:防止接下来的case语句块执行
- 优势:性能较高
- 缺陷:条件有大量限制,只能做==比较
- 使用场景:常用于高效匹配时
- if:
- 迭代
- while:
- while(条件){语句块}
- 当条件为真执行
- 使用场景:循环次数已知/未知,事件等待
- 小技巧:
- n–,执行n次
- –n,执行n-1次
- for:
- for(初始化(只执行一次); 条件(每次循环前检查); 迭代(每次循环后执行)) {语句块}
- 范围for循环:用于迭代容器或序列
- 使用场景:循环次数已知,复杂迭代(比如多变量迭代)
- 小技巧:(执行次数 == 区间个数)
- =n <m / =m >n 则执行m-n次
- =n <=m / =m >=n 则执行m-n + 1次
1 2 3
do { //循环体 } while (条件);
展开
- do while:先执行循环体,再检查条件, 也就是循环体至少执行一次
- while:
- 跳转
- break: 退出本次循环,继续循环外的指令
continue: 跳过本次循环体中剩余的语句,继续执行下一次循环的循环体
1 2 3 4
goto 标签名; // ...这里不执行 标签名: // ```代码
展开
- goto:无条件跳转语句,直接跳转到程序中的指定标签位置
左值,右值,左值引用,右值引用
- 左值:
- 特点:可寻址的内存、表达式结束不会立即销毁、可以修改值,有符号名,可以作为赋值运算符的左右操作数,可以作为递增减运算符的操作数
- 常见形式:字符串字面值,变量,赋值、前置递增递减表达式返回值,……
- const左值:不可以修改值(包括字符串字面值,和被const修饰的变量)
- 右值:
- 特点:不可寻址的内存、表达式结束立即销毁、不可修改值,没有符号名,仅能作为赋值运算符的右操作数,不能作为递增减运算符的操作数
- 常见形式:在除了字符串的其他字面值,变量作为赋值运算符的右操作数,算术、逻辑、关系、位运算、后置递增递减表达式返回值,函数非引用返回值……
- 纯右值:普通右值
- 将亡值:通过std::move转换后的右值,表达式结束不会立即销毁,可以寻址
- const右值:纯右值本身就是常量,它不可被赋值,将亡值可以是非常量,move转换给非常量
- 左值引用:
- type & name = val;
- 定义时必须初始化,否则编译错误
- 可以赋值,但更改的是绑定对象的值,而非绑定另一个对象
- 引用类型和绑定对象类型要严格匹配
- 可以被左值引用绑定的?非常量左值
引用不是对象,不占用内存这句话需要从多种角度理解(实际中会站在使用角度)- 从使用角度/规范上,无法获取引用本身地址,只能获取绑定对象的地址,这句话看起来是正确的
- 但底层实现上,引用其实是int* const r = &a;常量指针,所以它是对象,占用内存
- 引用是左值吗?
- 在规范上,它不是对象,因此没有左值右值之分
- 在使用上,使用的是它绑定的对象,它是左值
- 函数返回值
- 非引用:返回值是右值,可以理解为创建临时变量type temp = x(返回值),temp是纯右值,返回值需要能赋值给type
- 引用:返回值是左值,可以理解为直接返回x,返回值需要能赋值给type&
- 要注意返回局部变量情况,在函数调用后x生命周期结束,返回值未定义,很可能造成崩溃(去使用时)
- 对常量的引用:返回值是const左值,可以理解为直接返回const x,返回值需要能赋值给const type&
- 左值引用作用:
- 避免现有对象拷贝,节省内存开销
- 函数引用形参,直接操作传入的对象而非副本
- 函数引用形参,实现多返回值
- 函数引用返回值,实现链式调用
- 对const的左值引用
- 不能通过该引用修改所绑定对象的值
- 引用类型和绑定对象类型允许隐式类型转换
- 可以被对const的左值引用绑定的?常量左值,非常量左值,纯右值,将亡值
- 对const的左值引用绑定右值时,延长右值的生命周期,右值随着引用销毁后销毁
- 右值引用:
- type && name = val;
- 定义时必须初始化,否则编译错误
- 可以赋值,但更改的是绑定对象的值,而非绑定另一个对象
- 可以被右值引用绑定的?
- 纯右值
- 将亡值
std::move()
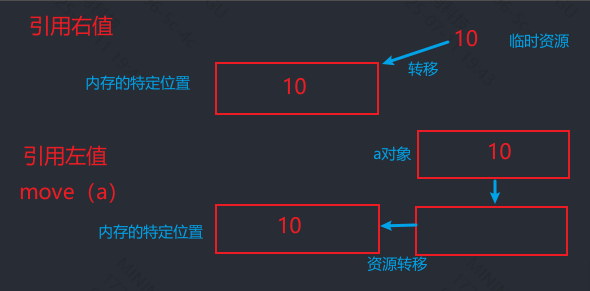
- 左值强制转化为将亡值,当初始化/赋值给其他对象时,左值的资源转移到右值引用的地址,资源随着引用销毁后销毁
- 右值引用绑定纯右值后,将临时资源转移到右值引用的地址,资源随着引用销毁后销毁
- 作用:
- 相比于对const的左值引用,右值引用可以避免拷贝临时资源的同时,允许对右值操作
- 移动语义:对于不再需要的对象直接将资源移动到另一个对象,而非拷贝,节省内存开销
使用场景:移动构造,移动赋值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74
class A { private: char* data; int size; public: // 1. 默认构造函数 A() : data(nullptr), size(0) {} // 3. 拷贝构造函数 A(const A& other) {//不会发生自赋值,因为other是已有的对象,要构造新的对象,他们一定是不同的对象 size = other.size; if (other.data) { data = new char[size + 1]; strcpy(data, other.data); } else { data = nullptr; } } // 4. 拷贝赋值运算符 A& operator=(const A& other) { if (this == &other) { return *this; } delete[] data; size = other.size; if (other.data) { data = new char[size + 1]; strcpy(data, other.data); } else { data = nullptr; } return *this; } // 5. 移动构造函数 A(A&& other) noexcept {//同样这个构造也不会发生自赋值 data = other.data; size = other.size; other.data = nullptr; other.size = 0; } // 6. 移动赋值运算符 A& operator=(A&& other) noexcept { if (this == &other) { return *this; } delete[] data; data = other.data; size = other.size; other.data = nullptr; other.size = 0; return *this; } // 7. 析构函数 ~A() { delete[] data; } // 辅助函数 const char* getData() const { return data ? data : ""; } int getSize() const { return size; } };
展开
完美转发:将函数的参数以左值或右值的形式完美传递给另一个函数
1 2 3 4 5 6 7 8 9 10 11
void process(int& i) { std::cout << "处理左值: " << i << std::endl; } void process(int&& i) { std::cout << "处理右值: " << i << std::endl; } template<typename T> void logAndProcess(T&& param) { process(std::forward<T>(param)); }
展开
- 引用折叠
- 规则:(模板类型、实参是左值/左值引用/右值/右值引用、&符号折叠为几个)
- T& -> & == &
- T&& -> & == &
- T& -> && == &
- T&& -> && == &&
- 当实参是左值/左值引用时,T&&为T&,当实参是右值/右值引用时,T&&为T&&
- 触发条件:
- 模板实例化
- 自动类型推导,包括auto关键字和decltype
- 作用:
- 确保组合不会得到引用的引用(不合法)
- 规则:(模板类型、实参是左值/左值引用/右值/右值引用、&符号折叠为几个)
- 万能引用
- T&& 可以绑定到左值或右值,并保证值类别
- std::forward<T>(param):保持param的原始值类别(左值/右值)
- 作用:编写既能接受左值、又能接受右值参数的模板代码
- 引用折叠
- 对const的右值引用
- 不能通过该引用修改所绑定对象的值
- 可以被对const的右值引用绑定的?纯右值,将亡值
- 一般不会使用
std::ref() std cref()
- 引用包装器std::ref,通过reference_wrapper包装,代替原本会被识别的值类型,防止拷贝,但它不能使被包装的对象变成引用
- 比如bind / thread ,如果关联的函数带有引用的形参,我们应该向万能引用参数传递引用,需要用ref / cref 包装
本文由作者按照 CC BY 4.0 进行授权