VulkanTutorial(18`Multisampling,Compute shaders)
Multisampling
我们不希望渲染效果有锯齿,它是由于像素分辨率导致的,解决问题的方式之一时多采样抗锯齿MSAA, 普通的光栅化渲染方式,每个像素有一个采样点,如果采样点在图元内,就绘制颜色,否则保留空白,由于分辨率,边缘处就会形成锯齿 MSAA是每个像素多个采样点,如果采样点在图元内,就让颜色*权重,否则采样点颜色为0,将一个像素内所有采样点颜色相加即像素颜色
Getting available sample count
根据VkPhysicalDeviceProperties中提取样本的确切最大数量,我们需要考虑(physicalDeviceProperties.limits.framebufferColorSampleCounts & physicalDeviceProperties.limits.framebufferDepthSampleCounts)缓冲区能同时支持的最大样本数, 在pickPhysicalDevice物理设备选择函数中调用
Setting up a render target
我们需要建立新的多采样image缓冲区(每个像素多个采样点),但是它不能直接呈现,需要将它解析为普通image缓冲区(每个像素一个采样点) 修改createImage函数,添加新的VkSampleCountFlagBits参数,以便修改imageInfo.samples = numSamples;并更新所有调用的函数 添加一个createColorResources函数,在这里创建image和imageview,并在initVulkan中调 用,不要忘记调整窗口时Destroy和重新创建
Adding new attachments
在renderpass中,首先更新颜色和深度附件sample为msaaSamples作为多重采样颜色和深度附件,添加新的解析颜色附件和引用 修改createFramebuffers,并添加新的图像视图 修改createGraphicsPipeline中的rasterizationSamples = msaaSamples;使用多个采样点 放大看没有锯齿了 
Compute Shader
GPU计算功能
计算着色器可以在GPU上完成CPU的计算功能,最好是计算成本高的部分且不需要在CPU的主内存和GPU的内存之间移动的数据,因为GPU有很强的高度并行化能力 可以使用GPU的计算能力的一些示例包括图像处理 可见性测试、后期处理、高级照明计算、动画、物理(例如用于粒子系统/流体模拟)等等 如果没有计算着色器,现代游戏和应用程序中的许多效果要么无法实现,要么运行速度会慢得多 计算部分与图形管线完全分离,可以看下图 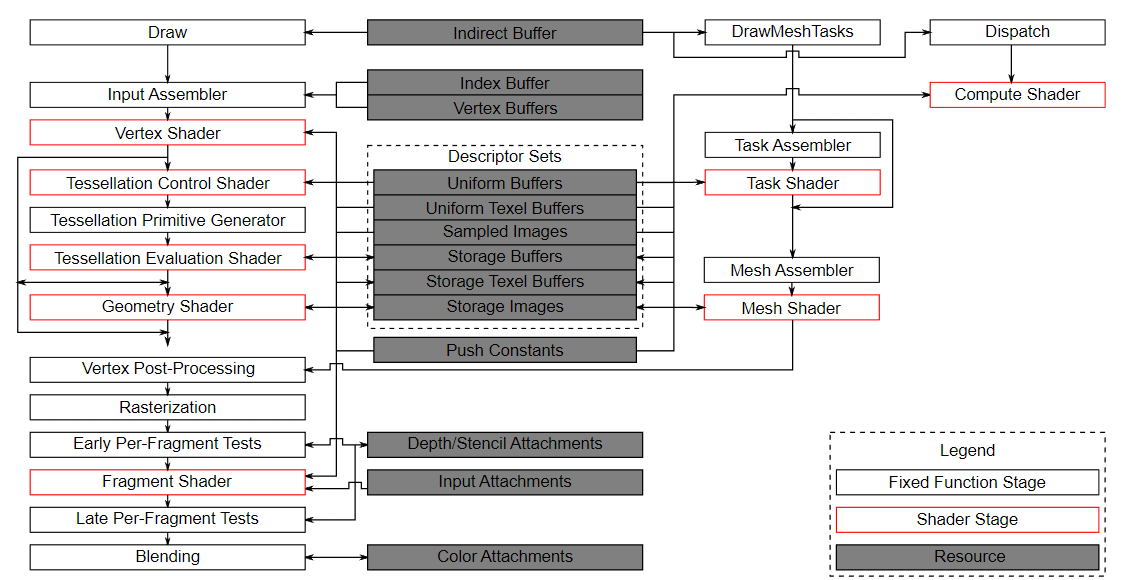 其中最左边部分是传统图形渲染管线(顶点数据,顶点着色器,光栅化等),右边不是图形渲染管线的一部分,它包括computerShader(最右边),因此我们可以在任意阶段使用它
其中最左边部分是传统图形渲染管线(顶点数据,顶点着色器,光栅化等),右边不是图形渲染管线的一部分,它包括computerShader(最右边),因此我们可以在任意阶段使用它
粒子系统
本节目标是实现一个简单的GPU粒子系统 传统CPU粒子系统数据存储在CPU中,每帧的新数据重新创建顶点缓冲区,然后再次传输到GPU的内存中,以便绘制它,每次都需要CPU到GPU的数据传输,显然非常昂贵。 使用基于GPU的粒子系统,不再需要这种往返,顶点仅在开始时上传到GPU,所有更新都使用计算着色器在GPU的内存中完成
缓冲区(读取存储)介绍
到目前为止,我们一直使用CPU写入数据,只在GPU上读取数据。引入了不同缓冲区用于传输 计算着色器引入的一个重要概念是任意读取和写入缓冲区的能力(可以在任何shader(GPU)对SSBO读取写入操作), Vulkan提供了两种专用缓冲区: 1·Shader storage buffer objects (SSBO)着色器存储缓冲区对象: 允许着色器从缓冲区读取和写入缓冲区,它可以任意大 你可能会认为SSBO是一个新的方式创建的缓冲区,其实它仅是通过指定一些标志的顶点缓冲区 VK_BUFFER_USAGE_VERTEX_BUFFER_BIT用作顶点着色器读取的顶点缓冲区(图形管线) VK_BUFFER_USAGE_STORAGE_BUFFER_BIT用作计算着色器的写入的存储缓冲区(计算过程) VK_BUFFER_USAGE_TRANSFER_DST_BIT 标志,以便我们可以将数据从主机传输到GPU(在开始时传输一次) VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT希望着色器存储缓冲区只留在GPU内存中 2·Storage images 存储图像: 计算着色器也可以用于图像操作(虽然本节不会使用),允许您从图像读取和写入图像,典型的用例是将图像效果应用于纹理,进行后期处理或生成mip贴图 VK_IMAGE_USAGE_SAMPLED_BIT作为片段着色器中的图像采样 VK_IMAGE_USAGE_SAMPLED_BIT作为计算机着色器中的存储图像 在计算着色器中可能如下所示:
1
2
3
4
layout (binding = 0, rgba8) uniform readonly image2D inputImage;
layout (binding = 1, rgba8) uniform writeonly image2D outputImage;
vec3 pixel = imageLoad(inputImage, ivec2(gl_GlobalInvocationID.xy)).rgb;
imageStore(outputImage, ivec2(gl_GlobalInvocationID.xy), pixel);
展开
图像格式的rgba8,readonly和writeonly限定符,告诉实现我们将只从输入图像读取并写入输出图像 imageLoad和imageStore在计算着色器中执行存储图像的阅读和写入
Compute queue families
如果想要使用计算着色器,需要显卡支持computer queuefamily 因此修改findQueueFamilies函数,让它支持VK_QUEUE_GRAPHICS_BIT && VK_QUEUE_COMPUTE_BIT(我们将使用一个既可以进行图形操作又可以进行计算操作的队queuefamily),以便更新物理设备选择 添加新的vkGetDeviceQueue,以便从这个队列家族中获得一个computeQueue
ComputePipeline
添加新的createComputePipeline创建计算管线函数,此ComputePipeline和GraphicsPipeline类似,,但都包含shader model, PipelineLayout模块,ComputePipeline不涉及任何光栅化状态,因此它的状态比图形管道少得多
data,SSBO
创建新的createShaderStorageBuffers以便创建粒子数据以及SSBO缓冲区函数 data: 创建Particle结构体,和vertex结构体几乎没有区别,除了数据属性不同 通过for循环指定粒子个数次,将所有粒子数据存入到vector< Particle > buffer: 然后向往常一样,先创建stagingBuffer,将刚刚的data写入到其中, 创建新的vector shaderStorageBuffers,通过copybuffer将stagingBuffer中data拷贝到SSBO中 现在粒子data都在SSBO中
Descriptors
createComputeDescriptorSetLayout就像uniformbuffer一样,我们也要创建Descriptor,以便可以将buffer传输到shader中 描述符需要设置VK_SHADER_STAGE_COMPUTE_BIT,以使它们可以被计算阶段访问 但是我们需要array数组形式,这是因为粒子系统非静止的,因此每一帧都要知道上一帧的粒子位置(读取),这样就可以计算出新的位置并写入SSBO(写入) 上面读取和访问是在createComputeDescriptorSets新的函数中将两者传递给计算着色器来完成的 不要忘记更新createDescriptorPool,修改VK_DESCRIPTOR_TYPE_STORAGE_BUFFER类型
work groups and invocations
我们先了解两个重要的计算概念:work groups and invocations,它们说明GPU的计算硬件如何在三个维度(x、y和z)中处理计算任务(即GPU计算硬件如何工作的) work groups定义GPU的计算硬件如何形成和处理计算工作负载 每个工作组都是执行相同计算着色器的invocations调用的集合,调用可以并行运行 工作组和调用的维数取决于输入数据的结构,例如,如果你处理一个一维数组,只需要为两者指定x维
Compute shaders
首先是一个ubo的缓冲区,传入deltaTime
1
2
3
4
5
6
7
8
9
10
……
layout(std140, binding = 1) readonly buffer ParticleSSBOIn {
Particle particlesIn[ ];
};
layout(std140, binding = 2) buffer ParticleSSBOOut {
Particle particlesOut[ ];
};
layout (local_size_x = 256, local_size_y = 1, local_size_z = 1) in;
……
展开
分别为上一帧的粒子数据,和将写入的SSBO std 140是一个内存布局限定符,用于确定着色器存储缓冲区的成员元素如何在内存中对齐 layout定义了当前工作组中该计算着色器的调用次数,当我们处理线性1D粒子阵列时,只需要在local_size_x中指定x维的数字 gl_GlobalInvocationID内置变量唯一标识当前调度中的当前计算着色器调用的变量。我们用它来索引我们的粒子数组
Running compute commands
创建新的recordComputeCommandBuffer,就像调用图形的绘制命令一样,我们想要GPU计算工作需要调用vkCmdDispatch命令 vkCmdDispatch将在x维度中分派PARTICLE_COUNT/ 256本地工作组,首先它不考虑其他维度 除以256是因为在shader中定义了工作组中的每个计算着色器将执行256次调用,如果我们有4096个粒子,每个工作组运行256个计算着色器调用,即有PARTICLE_COUNT/ 256 = 16个工作组
QueueSubmit,Synchronizing
在drawFrame中我们也要将计算命令vkQueueSubmit到队列,但是我们要正确设置Synchronizing 有两个单独的提交,我们将使用信号量和围栏,以确保顶点着色器不会开始获取顶点,直到计算着色器完成更新它们
Drawing the particle system
在recordCommandBuffer中vkCmdBindVertexBuffers绑定SSAO 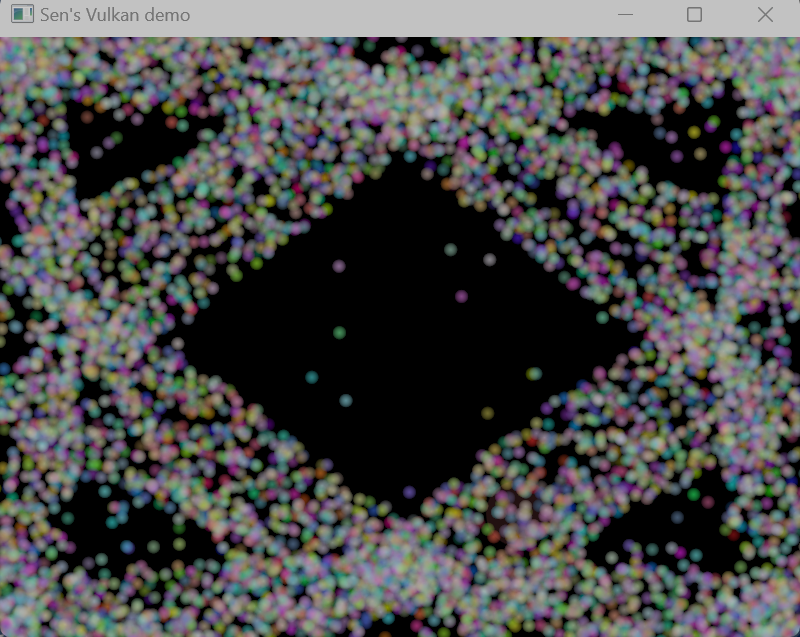
————————————-vulkan tutorial 完结——————————————–